
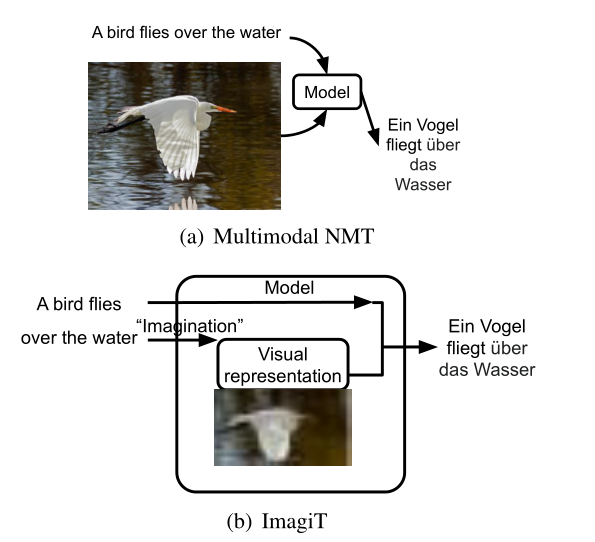
ImagiT
简介
提出了一个新的模型ImagiT。它结合了机器翻译和图像生成,首先学习从源句子生成图像,然后利用源句子和生成的图像(其实是视觉表示)来生成目标翻译。这样一来,在推理的时候就不需要再输入对应的图片了。
模型介绍
ImagiT 利用了端到端机器翻译的编码器-解码器结构。在编码器和解码器之间,增加了一个imagination来生成语义等价的视觉表示。模型由以下模块组成:源文本编码器、生成想象网络、图像描述、多模态聚合和翻译解码器。
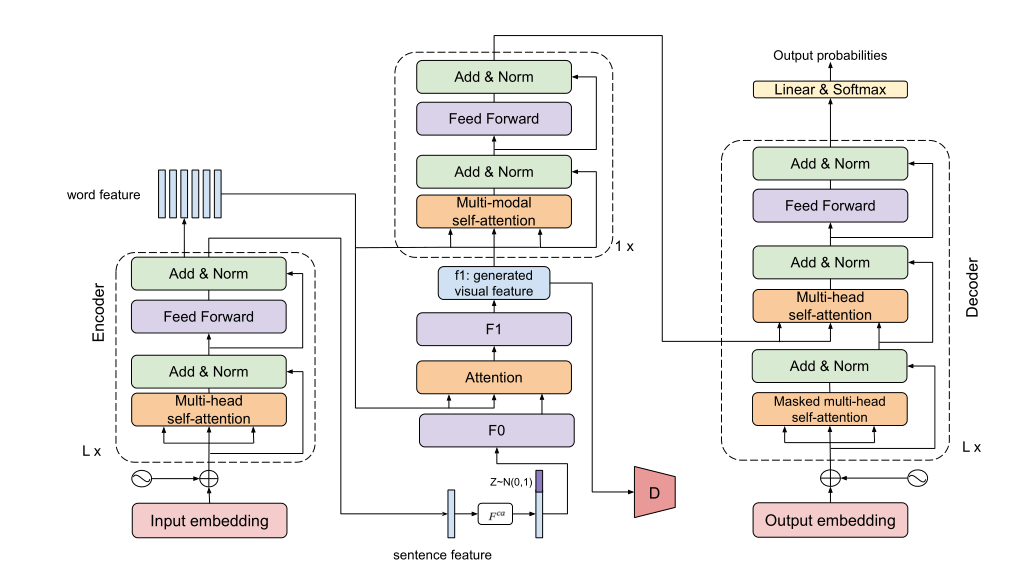
给定一个源语言句子,ImagiT 首先对其进行编码,并通过一个注意力生成器将文本表示转换为视觉特征,这可以有效地捕获全局和局部级别的语义,并且生成的视觉表示可以被认为是语义等价的重建句子。多模态聚合旨在聚合文本和视觉特征。最后,模型学习基于联合特征生成目标语言句子。
文本编码器
编码器就是基于的多层Transformer编码器
生成想象网络
该网络基于条件增强的常见做法(见原文),先对文本进行增强,然后通过Attngan的做法(见原文):F0、F1是两个视觉特征转换器,有相似的架构,包含一个全连接层和四个反卷积层,以获得图像大小的特征向量。
图像描述
一个单层的Transformer的编码器-解码器结构,有效地增强想象的视觉的语义一致性特征并准确反映底层语义。本部分是预训练好的。
多模态聚合
视觉虽然承载了更丰富的信息,但也包含了不相关的噪声。仿照(原文)的做法,将生成的特征图的空间特征添加到源句中,即注意力查询向量是文本和视觉嵌入的组合,然后再进行图像感知注意力。
结构总结
简单来说模型就是基于编码器-解码器架构的模型,在编码器与解码器传输的中间引入了类似于对抗网络的生成结构和一个单层的图像描述生成结构(仿照Mirrorgan的方式),通过这一部分将传统架构中编码器传给解码器的隐式变量进行改善,比原有的架构包含了更多的信息。
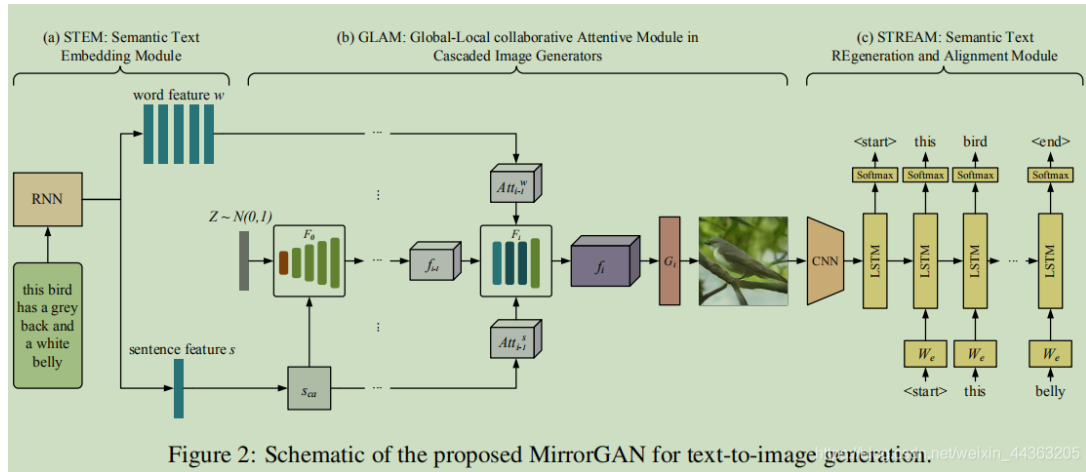
MirrorGAN:
训练
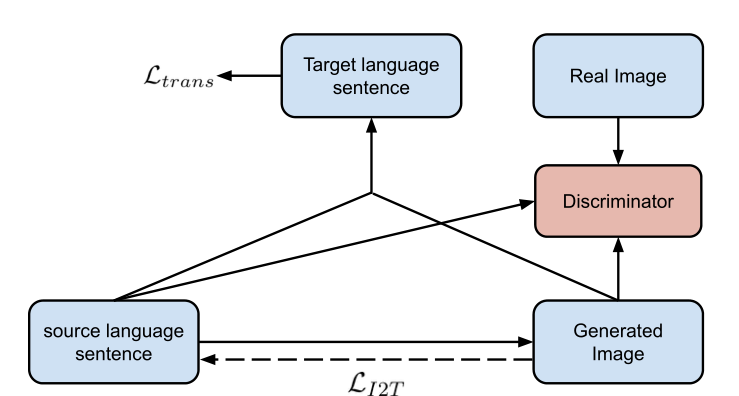
要计算两部分的损失,第一部分是生成的翻译和真实翻译的损失,另一部分是生成的图像和真实图像的损失(生成-判别)。总的损失函数:
- 生成器:
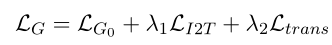
- 鉴别器:
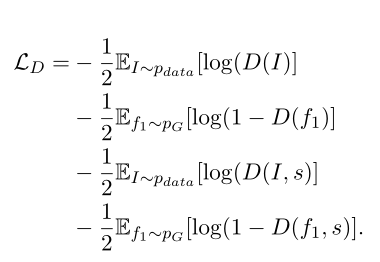
实验结果
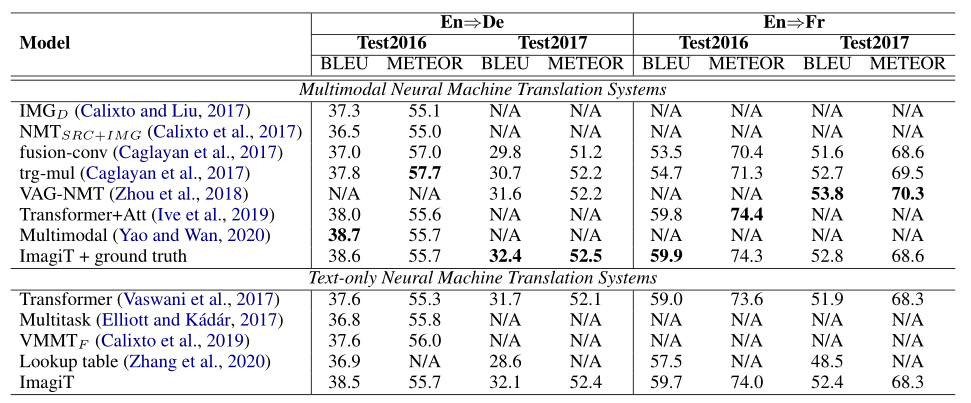
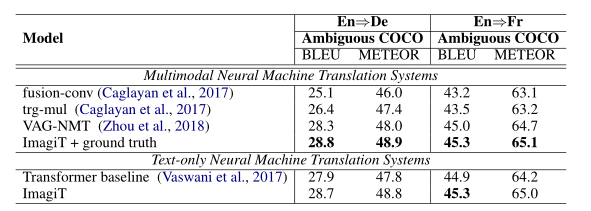
实验实验了三种数据集,Multi30K、Ambiguous COCO、MS COCO,baseline是纯文本的经典的基于Transformer架构的机器翻译模型。
首先是在Multi30K数据集上对比了输入图像和不输入图像两种方式的结果。
接着在Ambiguous COCO数据集上对比:
实验还通过问答的形式验证了有效性:
- 对于生成视觉特征的正确性。每个源语句生成中间视觉表示,查询每个视觉特征表示的真实图像特征,以根据余弦相似度找到其周围最接近的图像向量。然后测量 R@K 分数,它计算匹配图像在前 K 个最近邻域中的召回率。
- 视觉特征(imagination)如何指导翻译。将源句子的颜色词或者实体词进行屏蔽,这样一来,纯文本的翻译需要通过上下文推断,而多模态可以通过视觉判断,通过验证分数来证明有效性。
- 最后验证了大规模的外部数据可能会进一步提高 ImagiT 的性能。
总结
模型比纯文本 NMT 基线获得了显着改进,并且与 SOTA MNMT 模型相当。但也有着不足,比如对于难以场景化的翻译,该模型的效果不佳,因此在运用方面有着限制。