
SinDiffusion
USTC MSRA
前置
单图像生成(Single Image Generate)
- 单图像生成目的是通过学习一幅图像的内部patch分布来生成多样化的结果,具体而言就是使用一张图片进行训练,然后可以生成与原图内容相似的不同图片,并且可以用于图像编辑(Image editing)、图像协调(Image harmonization)等。

扩散模型
- 扩散模型的灵感来源于非平衡热力学过程,分为前向过程与后向过程,前向过程通过给一幅图片不断增加噪声,然后后向过程训练模型去噪的能力。
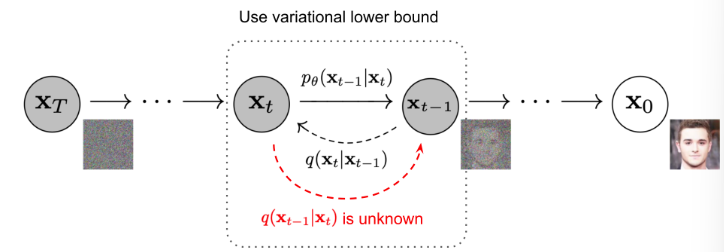
-
通过上述过程,模型可以通过一幅全噪声的图片,生成完整的图像,因此其也是一种生成式的模型。
-
与GAN相比,基于Diffusion的模型训练过程比较稳定(不需要对抗过程),有比较完备的数学公式推导,其过程可以用数学公式表述。
-
前向过程:
-
后向过程:
从采样即可得到恢复的图像:
-
Motivation
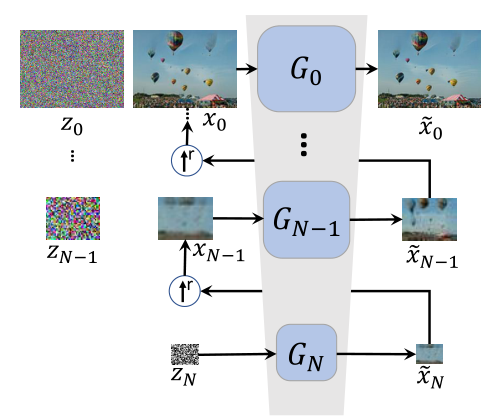
- 现有基于GAN的单图像生成存在错误累积问题:通过使用多个分辨率的图像训练多个模型,图像通过上采样不断增加分辨率,上个模型生成的图片经过上采样作为下个模型的输入,导致错误不断累积。

- 多样性不足:由于基于GAN的网络(比如SinGAN)的感受野是整个图像,所以网络更倾向于直接记住整个图像的内容,从而生成与训练图像完全相同的图像。
Methods
- 提出一种基于Diffusion模型的单图像生成模型SinDiffusion,可以在单一分辨率大小下,用一个模型学习图像内图像块之间的关系。
模型结构
- 扩散模型虽然也是一个多步生成过程,但它不存在累积误差的问题,因为扩散模型具有完备的数学表达,中间步骤的误差可以看作是噪声,在扩散过程中可以进行细化。
- 另一方面,设计了一种网络来限制扩散模型的对图像的感受野,以此让模型学习补丁统计信息,而不是记住整个图像,引入了基于图像补丁的去噪网络,因此模型可以学习到图像补丁之间的关系,增加了多样性。
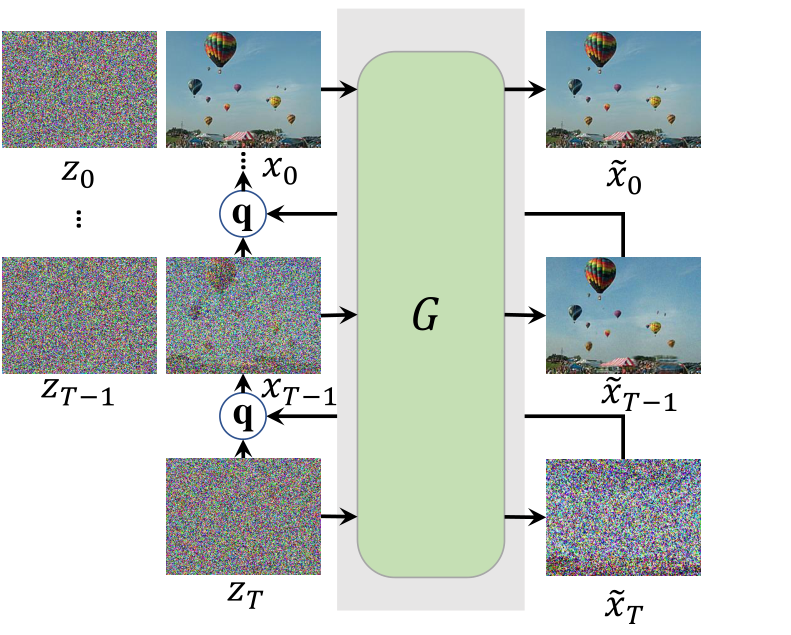
- 具体而言,引入Patch-Wise Denoising Network。原本的扩散模型的感受野覆盖整个图像,导致生成与训练图像相同的图像。修改后的SinDiffusion学习基于局部的图像补丁,最终可以生成不同的图像。
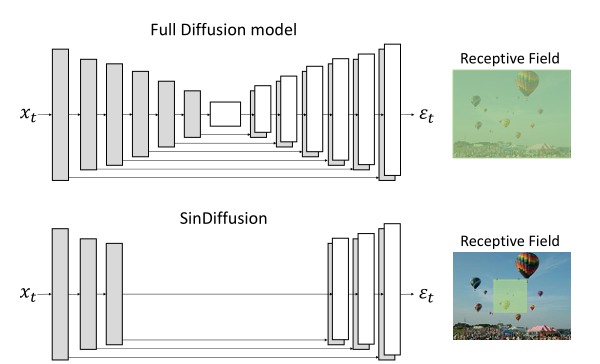
- 通过减少下样本和上样本操作来减小去噪网络的深度,这大大扩展了感受野。同时将原本深层使用的注意层去除,使得SinDiffusion成为一个适用于任意分辨率生成的全卷积网络。其次,通过减少每个分辨率中的时间嵌入Resblock来限制SinDiffusion的感受野。
训练
-
前向过程和后向过程与原始的Diffusion相同,选择
-
前向过程:
-
后向过程:
-
训练目标(损失):
-
Experiments
消融实验
-
Multi-scale v.s. Single-scale:SinGAN中每个尺度的GAN转换为扩散模型,从而提出了单图像生成的多尺度扩散模型。SinDiffusion的性能优于多尺度扩散模型。同时,与多尺度扩散模型相比,SinDiffusion的网络参数和计算量要小得多,这也体现了单尺度设计的优势。

-
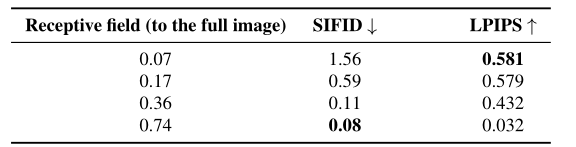
Receptive field:SinDiffusion用更小的感受野生成更多样化的图像。然而,生成图像的保真度(SIFID)随着感受野的增加而增加。因此,要采取了一个合适的感受野,以权衡图像质量和多样性。
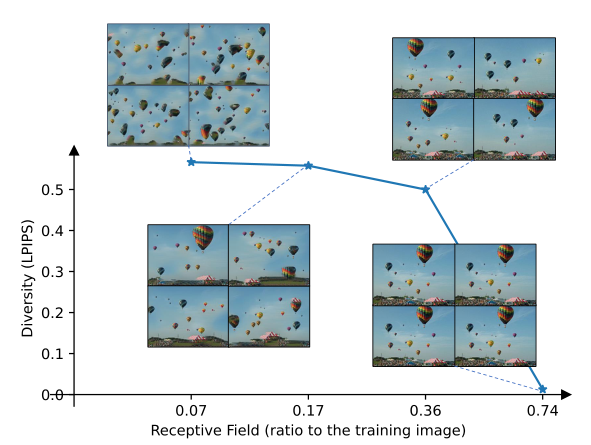
定性比较
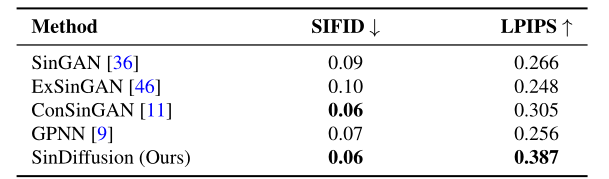
- 将SinDiffusion与SinGAN、ExSinGAN、ConSinGAN、GPNN进行比较。SinGAN、ExSinGAN和ConSinGAN算法在多尺度结构中由于误差累积而产生的结果存在伪影。GPNN缺乏泛化能力,生成的图像接近训练图像。相比之下,SinDiffusion生成的图像在保真度和多样性方面都表现得更好。

- 并且SinDiffusion可以生成不同分辨率的与训练图像相似的图像。

- 评分方面,图片质量衡量的指标选择SIFID(Single-Image Frechet Inception Distance),即测量生成图像与真实图像之间Patch-wise特征分布的偏差;为了评估生成图像的多样性,使用图像感知相似度指标LPIPS。在两个指标上达到了SOTA的性能。
下游任务
Text-guided image generation(文本指导图像生成)
- 为了从与给定文本对应的单个图像中生成图像,我们通过预先训练的视觉语言模型,即CLIP的梯度来指导采样过程。假设预先训练的扩散模型具有估计的均值,通过扰动均值可以生成与给定文本L对应的图像,其公式如下:
- 以往的方法在Single image设置下无法生成与文本相对应的图像。这表明我们提供了一种通过高级语义控制单幅图像模型的有效方法。


- 而将SinDiffusion与之前的几种方法进行比较,即ManiGAN、StyleMC和StyleCLIP。结果表明,与之前的方法相比,SinDiffusion可以生成更符合输入文本的图像
Image outpainting(图像外绘)
- 图像外绘旨在生成超出图像边缘的内容。SinDiffusion模型从训练图像中学习了补丁的内部分布,因此它固有地能够想象给定图像之外的内容,在采样过程中通过替换给定区域来生成训练图像之外的内容。假设一个预训练的扩散模型具有迭代隐变量,通过替换给定的区域来绘制自然图像,其公式如下:
- 结果展示


Other image manipulation task(其他)
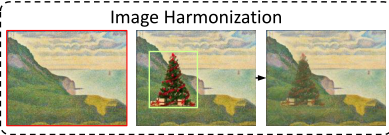
- SinDiffusion也可以应用于先前方法中的图像处理任务,即图像编辑、图像协调和图像到图像的转换。从参考图像生成新的图像,设计采样过程如下:
-
其中,代表低通滤波,为参考图像在时间步长处的加入噪声形式。基于这个公式可以控制扩散模型的采样过程。
-
Paint-to-image Translation
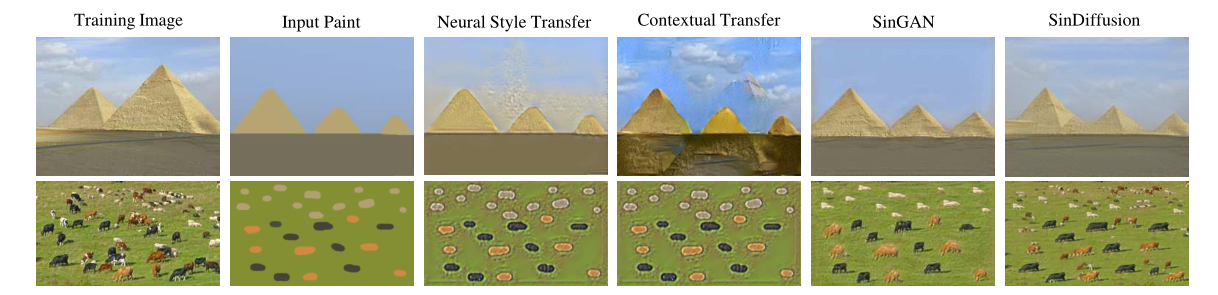
-
Image Editing

- Image Harmonization
Conclusion
- 首次尝试探索单幅图像生成的扩散模型,并提出了一个新的框架,称为 Single-image Diffusion
Model (SinDiffusion) - 揭示了感受野在生成多样化图像中起着重要作用,并设计了一个Patch-wise去噪网络来生成高质量和多样化的图像。
- 利用预训练的SinDiffusion模型,研究了各种图像处理任务。在各种自然图像和Places50数据集上的大量实验证明了我们方法的有效性。并且在SIFID和LPIPS指标方面达到了最先进的性能。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 CoorDi's Blog!