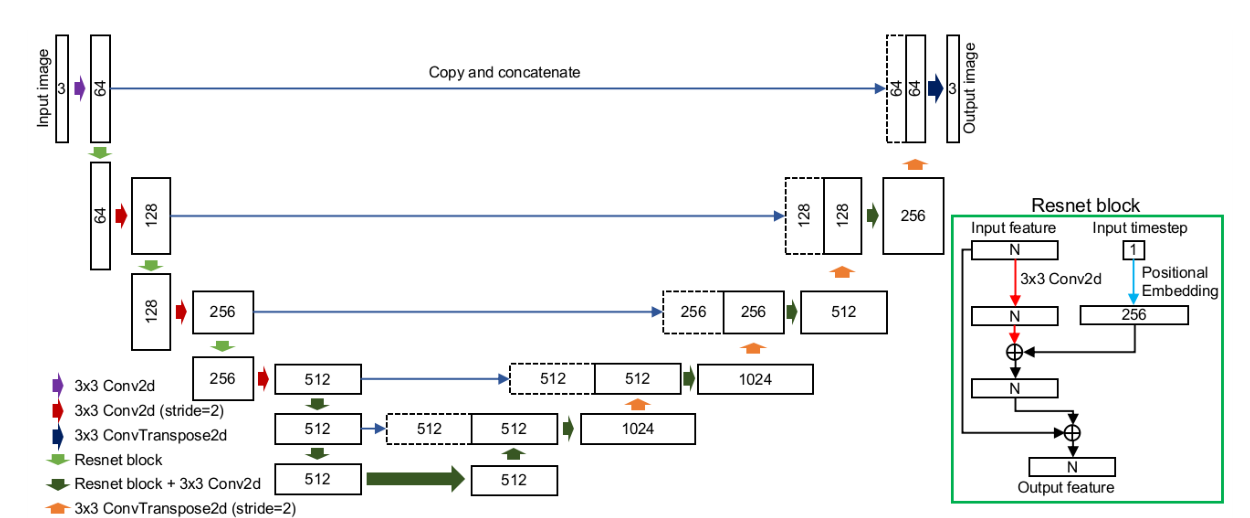
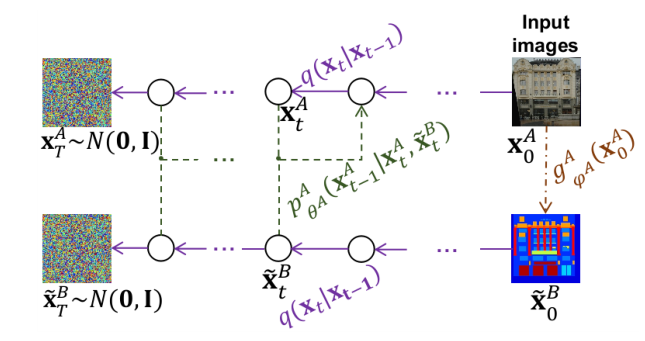
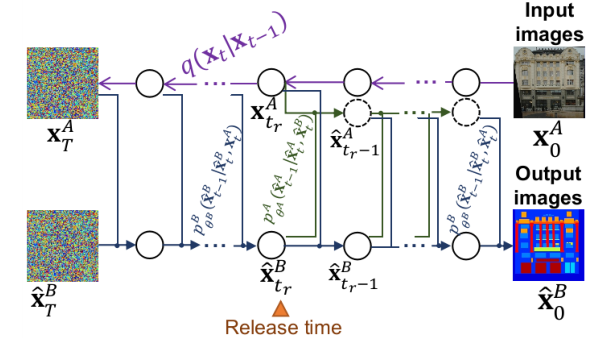
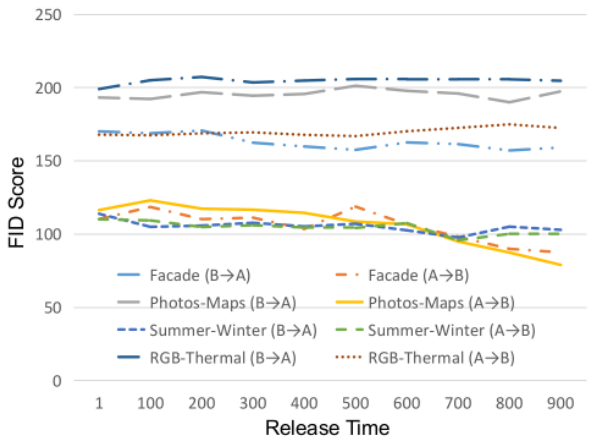
针对于反向过程的损失将变为:
Lθ(θA,θB)=Et,x0A,ϵ[ϵ−ϵθAA(xt(x0A,ϵ),x~tB,t)2]+Et,x0B,ϵ[ϵ−ϵθBB(xt(x0B,ϵ),x~tA,t)2]
而对于DSM的参数ϕA与ϕB,固定反向过程中的参数θ∗,最小化损失为:
Lϵϕ(ϕA,ϕB)=Et,x0B,ϵ[ϵ−ϵθAA(xt(gϕBB(x0B),ϵ),xt(x0B,ϵ),t)2+ϵ−ϵθBB(xt(x0B,ϵ),gϕBB(xt(x0B),ϵ),t)2]+Et,x0A,ϵ[ϵ−ϵθBB(xt(gϕAA(x0A),ϵ),xt(x0A,ϵ),t)2+ϵ−ϵθAA(xt(x0A,ϵ),gϕAA(xt(x0A),ϵ),t)2]
对于这个损失函数,还需要引进规范化,称为Cycle-consistency Loss,被定义为:
Lcycϕ(ϕA,ϕB)=Ex0B[∥gϕAA(gϕBB(x0B))−x0B∥1]+Ex0A[∥gϕBB(gϕAA(x0A))−x0A∥1]
最后,针对于DSM的参数的损失:
Lϕ(ϕA,ϕB)=Lϵϕ(ϕA,ϕB)+λcycLcycϕ(ϕA,ϕB)
其中,λcyc是权重。