Introduction
现在 (2023年3月29日) 所谓的扩散模型 大多数指的是2020年所发表的Denoising Diffusion Probabilistic Models ,简称为DDPM 。其实“扩散”的思想更早见于Diffusion Probabilistic Models Sohl-Dickstein et al. ),但是由于当时的算力以及模型计算Loss是基于图像而不是噪声,所以没有很好的效果。
在2020年以后,许多基于原始DDPM模型的工作开始大量出现,包括对模型的架构、采样过程、图像预处理的改进,当然扩散的思想也不再局限于计算机视觉(CV)领域,而是开始应用于多模态(Multimodal)、自然语言处理(NLP)、语音(Audio)等各种领域。而在2022年,OPENAI的DALL·E 2 以及后来的NovalAI 的成功,让扩散模型商用化(当然训练模型所用的资源也是我们无法想象的😱),也让“扩散模型”进入了大众的视野(比如我😁)。
作为一种生成式 模型,DDPM的出现打破了GAN、VAE等在图像生成领域的“垄断”,它有着很强(?)的数学理论,解决了生成前辈们的存在的一些问题,当然DDPM也借鉴了一些前述工作的成果。鉴于DDPM的成功,本文所说的扩散模型指的是DDPM 以及基于其的改进模型。
Background
在介绍DDPM之前,首先要整理一下其所涉及的一些数学背景,以免在后面推导时不知所云。可以直接跳到下一部分🦁。
Markov Chain
马尔科夫链/过程
学过随机过程的话应该对Markov 十分熟悉了,这里只讨论与扩散模型相关的有限状态的离散时间时齐的马尔可夫链。假设一个状态链,其下一个过程只与当前的状态有关,而与其他的更久远的状态无关。
我们观测一个随机状态的变化,其序列为{ x 0 , x 1 , . . . , x t , . . . , x T } \{x_0,x_1,...,x_t,...,x_T\} { x 0 , x 1 , ... , x t , ... , x T } p ( x t + 1 ∣ x t , x t − 1 , . . . , x 0 ) p(x_{t+1}|x_t,x_{t-1},...,x_0) p ( x t + 1 ∣ x t , x t − 1 , ... , x 0 ) p ( x t + 1 ∣ x t ) p(x_{t+1}|x_t) p ( x t + 1 ∣ x t )
p ( x t ∣ x t + 1 ) = p ( x t ) p ( x t + 1 ∣ x t ) p ( x t + 1 ) p(x_{t}|x_{t+1})=\frac{p(x_{t})p(x_{t+1}\mid x_{t})}{p(x_{t+1})}
p ( x t ∣ x t + 1 ) = p ( x t + 1 ) p ( x t ) p ( x t + 1 ∣ x t )
Gaussian Distribution
高斯分布与其相关性质
高斯分布又称为正态分布,对于一个连续时间的高斯分布,若随机变量X X X μ \mu μ σ \sigma σ X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) X ∼ N ( x ; μ , σ 2 ) X\sim N(x;\mu,\sigma^2) X ∼ N ( x ; μ , σ 2 )
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 f(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(x-\mu)^{2}}{2\sigma^{2}}}
f ( x ) = σ 2 π 1 e − 2 σ 2 ( x − μ ) 2
高斯分布有很多性质,常见的有:
假设有实数a a a b b b X ∼ N ( μ , σ 2 ) X\sim N(\mu,\sigma^2) X ∼ N ( μ , σ 2 ) a X + b ∼ N ( a μ + b , ( a σ ) 2 ) a X+b\sim N(a\mu+b,(a\sigma)^2) a X + b ∼ N ( a μ + b , ( aσ ) 2 )
假设X X X Y Y Y X ∼ N ( μ X , σ X 2 ) X\sim N(\mu_{X},\sigma_{X}^{2}) X ∼ N ( μ X , σ X 2 ) Y ∼ N ( μ Y , σ Y 2 ) Y\sim N(\mu_{Y},\sigma_{Y}^{2}) Y ∼ N ( μ Y , σ Y 2 ) X + Y ∼ N ( μ X + μ Y , σ X 2 + σ Y 2 ) X+Y\sim N(\mu_{X}+\mu_{Y},\sigma_{X}^{2}+\sigma_{Y}^{2}) X + Y ∼ N ( μ X + μ Y , σ X 2 + σ Y 2 )
Reparameterization
重参数化技术
假设有一系列样本x x x p θ ( x ) p_{\theta}(x) p θ ( x )
L ( θ , ϕ ) = E x ∼ ρ ϕ ( x ) [ f θ ( x ) ] L(\theta,\phi)=\mathbf{E}_{x\sim\rho_\phi(x)}[f_\theta(x)]
L ( θ , ϕ ) = E x ∼ ρ ϕ ( x ) [ f θ ( x )]
我们要对其进行梯度计算以进行反向传播,L L L θ , ϕ \theta,\phi θ , ϕ ∇ θ L ( θ , ϕ ) \nabla_\theta L(\theta,\phi) ∇ θ L ( θ , ϕ ) ∇ ϕ L ( θ , ϕ ) \nabla_\phi L(\theta,\phi) ∇ ϕ L ( θ , ϕ )
对于∇ θ L ( θ , ϕ ) \nabla_\theta L(\theta,\phi) ∇ θ L ( θ , ϕ ) ∇ θ L ( θ , ϕ ) = ∇ θ E x ∼ p ϕ ( x ) [ f θ ( x ) ] = E x ∼ p ϕ ( x ) [ ∇ θ f θ ( x ) ] \nabla_{\theta}\mathsf{L}(\theta,\phi)=\nabla_\theta\mathbf{E}_{x\sim p_{\phi}(x)}\left[f_{\theta}(x)\right]=\mathbf{E}_{x\sim\mathcal{p}_{\phi}(x)}\left[\nabla_θ f_{\theta}(x)\right]
∇ θ L ( θ , ϕ ) = ∇ θ E x ∼ p ϕ ( x ) [ f θ ( x ) ] = E x ∼ p ϕ ( x ) [ ∇ θ f θ ( x ) ]
然后可以根据Monte-Carlo方法求出:∇ θ L ( θ , ϕ ) ≈ 1 ∣ S ∣ ∑ s = 1 S ∇ θ f θ ( x ( s ) ) \nabla_{\theta}L(\theta,\phi)\approx\dfrac{1}{|S|}\sum\limits_{s=1}^S\nabla_\theta f_\theta\left(x^{(s)}\right)
∇ θ L ( θ , ϕ ) ≈ ∣ S ∣ 1 s = 1 ∑ S ∇ θ f θ ( x ( s ) )
其中x ( s ) x^{(s)} x ( s ) p θ ( x ) {p}_{\theta}(x) p θ ( x ) f f f θ \theta θ
对于∇ ϕ L ( θ , ϕ ) \nabla_\phi L(\theta,\phi) ∇ ϕ L ( θ , ϕ ) ∇ ϕ L ( θ , ϕ ) = ∇ ϕ E x ∼ p ϕ ( x ) [ f θ ( x ) ] = ∫ f θ ( x ) ∇ ϕ p ϕ ( x ) d x \nabla_\phi L(\theta,\phi)=\nabla_{\phi}\mathbf{E}_{x\sim\boldsymbol{p}_{\phi}(x)}\left[f_{\theta}(x)\right]=\int f_\theta(x)\nabla_\phi p_\phi(x)dx
∇ ϕ L ( θ , ϕ ) = ∇ ϕ E x ∼ p ϕ ( x ) [ f θ ( x ) ] = ∫ f θ ( x ) ∇ ϕ p ϕ ( x ) d x
此时Monte-Carlo方法并不能起作用,因为Monte-Carlo只能通过采样得到值,而不能告诉我们它的梯度是多少,简单来说就是“采样”这个过程不可微。
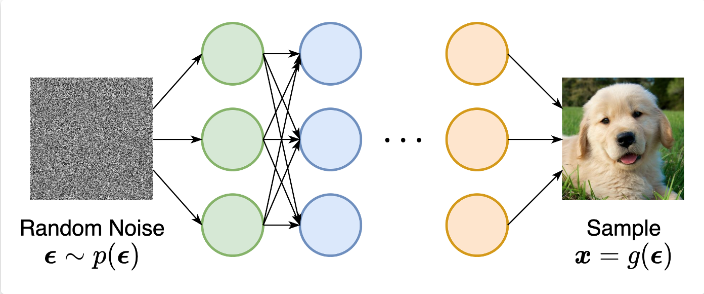
而重参数化就是把随机性从变量中“分离”出来,设一个确定性函数x = g ( ϕ , ϵ ) x=g(\phi,\epsilon) x = g ( ϕ , ϵ ) ϵ \epsilon ϵ ϵ \epsilon ϵ ∇ ϕ L ( θ , ϕ ) \nabla_\phi L(\theta,\phi) ∇ ϕ L ( θ , ϕ )
∇ ϕ L ( θ , ϕ ) = E ϵ ∼ p ( ϵ ) [ f θ ′ ( g ( ϕ , ϵ ) ) ∇ ϕ g ( ϕ , ϵ ) ] \nabla_{\phi}L(\theta,\phi)=\mathbf{E}_{\epsilon\sim p(\epsilon)}\left[f'_{\theta}(g(\phi,\epsilon))\nabla_{\phi} g(\phi,\epsilon)\right]
∇ ϕ L ( θ , ϕ ) = E ϵ ∼ p ( ϵ ) [ f θ ′ ( g ( ϕ , ϵ )) ∇ ϕ g ( ϕ , ϵ ) ]
因此,对于一个密度函数,要如何求得这个确定性函数😶?对于常见的数据分布,已经有很完备的推导了:
对于扩散模型,我们要用到是简单的高斯分布的重参数化,可以写为:
x = μ ( ϕ ) + σ ( ϕ ) ∗ ϵ x=\mu(\phi)+\sigma(\phi)*\epsilon
x = μ ( ϕ ) + σ ( ϕ ) ∗ ϵ
其中,ϵ ∼ N ( 0 , 1 ) \epsilon\sim N(0,1) ϵ ∼ N ( 0 , 1 )
Stochastic Differential Equation
随机微分方程
对于一个随机过程(比如布朗运动),我们能否用一个方程来表述呢(类似于一辆车行驶在公路上,我们可以用牛顿定律去描述)?随机届的Stochastic Differential Equation(简称为SDE)就是用来描述随机过程的工具。一般来说,对于概率上的SDE的一个典型的形式为:
d X t = μ ( X t , t ) d t + σ ( X t , t ) d B t \mathrm{d} X_{t}=\mu\left(X_{t}, t\right) \mathrm{d} t+\sigma\left(X_{t}, t\right) \mathrm{d} B_{t}
d X t = μ ( X t , t ) d t + σ ( X t , t ) d B t
B B B
X t + s − X t = ∫ t t + s μ ( X u , u ) d u + ∫ t t + s σ ( X u , u ) d B u X_{t+s}-X_t=\int_{t}^{t+s}\mu(X_u,u)\mathrm{d}u+\int_t^{t+s}\sigma(X_{u},u)\mathrm{d}B_{u}
X t + s − X t = ∫ t t + s μ ( X u , u ) d u + ∫ t t + s σ ( X u , u ) d B u
上述方程将连续时间的X t X_t X t 勒贝格积分 (Lebesgue integral)与伊藤微积分 (Itō calculus)之和,上过数学分析的应该对勒贝格积分有一些印象,伊藤微积分将微积分的概念扩展到随机过程中,分别详见勒贝格积分 与伊藤积分 。对于这个积分项,我们很直观的看出,对于一个s s s X t X_t X t μ ( X t , t ) \mu(X_t,t) μ ( X t , t ) σ ( X t , t ) 2 \sigma(X_{t},t)^2 σ ( X t , t ) 2 t t t μ \mu μ σ \sigma σ X t X_t X t
通过这样的一个过程,我们把x 0 x_0 x 0 x T x_T x T T T T Blog ,最后结果为:
d X τ = ( − μ ( x 1 − τ ) + σ ~ 2 ∂ x 1 − τ log p ( x 1 − τ ) ) d t + σ ( x 1 − τ ) d W ~ τ \mathrm{d} X_{\tau}=\Big(-\mu(x_{1-\tau})+\tilde{\sigma}^2\partial_{x_{1-\tau}}\log p(x_{1−\tau})\Big)dt+\sigma(x_{1-\tau})d\tilde{W}_\tau
d X τ = ( − μ ( x 1 − τ ) + σ ~ 2 ∂ x 1 − τ log p ( x 1 − τ ) ) d t + σ ( x 1 − τ ) d W ~ τ
Evidence Lower Bound(ELBO)
证据下界
ELBO可见于期望最大化和变分推理,尤其是了解过VAE模型的人。
假设存在一个隐变量z z z p ( x , z ; θ ) p(x,z;\theta) p ( x , z ; θ ) θ \theta θ z z z p ( x ) = ∫ p ( x , z ) d z p(x)=\int p(x, z)dz p ( x ) = ∫ p ( x , z ) d z
p ( x ) = p ( x , z ) p ( z ∣ x ) p(x)=\dfrac{p(x,z)}{p(z|x)}
p ( x ) = p ( z ∣ x ) p ( x , z )
从联合分布p ( x , z ) p(x,z) p ( x , z ) p ( x ) p(x) p ( x ) z z z
因此我们要换个方向去解决,用模型q ϕ ( z ∣ x ) q_{\phi}(z \mid x) q ϕ ( z ∣ x ) p ( z ∣ x ) p(z|x) p ( z ∣ x ) log ( p ( x ) ) \log(p(x)) log ( p ( x ))
log p ( x ) = log p ( x ) ∫ q ϕ ( z ∣ x ) d z = ∫ q ϕ ( z ∣ x ) ( log p ( x ) ) d z = E q ϕ ( z ∣ x ) [ log p ( x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) p ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) p ( z ∣ x ) q ϕ ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] + E q ϕ ( z ∣ x ) [ log q ϕ ( z ∣ x ) p ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] + D K L ( q ϕ ( z ∣ x ) ∥ p ( z ∣ x ) ) ≥ E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] \begin{aligned}
\log p(\boldsymbol{x}) & =\log p(\boldsymbol{x}) \int q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x}) d z \\
& =\int q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})(\log p(\boldsymbol{x})) d z \\
& =\mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}[\log p(\boldsymbol{x})] \\
& =\mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{p(\boldsymbol{x}, \boldsymbol{z})}{p(\boldsymbol{z} \mid \boldsymbol{x})}\right] \\
& =\mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{p(\boldsymbol{x}, \boldsymbol{z}) q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}{p(\boldsymbol{z} \mid \boldsymbol{x}) q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\right] \\
& =\mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{p(\boldsymbol{x}, \boldsymbol{z})}{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\right]+\mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}{p(\boldsymbol{z} \mid \boldsymbol{x})}\right] \\
& =\mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{p(\boldsymbol{x}, \boldsymbol{z})}{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\right]+D_{\mathrm{KL}}\left(q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x}) \| p(\boldsymbol{z} \mid \boldsymbol{x})\right) \\
& \geq \mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{p(\boldsymbol{x}, \boldsymbol{z})}{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\right]
\end{aligned}
log p ( x ) = log p ( x ) ∫ q ϕ ( z ∣ x ) d z = ∫ q ϕ ( z ∣ x ) ( log p ( x )) d z = E q ϕ ( z ∣ x ) [ log p ( x )] = E q ϕ ( z ∣ x ) [ log p ( z ∣ x ) p ( x , z ) ] = E q ϕ ( z ∣ x ) [ log p ( z ∣ x ) q ϕ ( z ∣ x ) p ( x , z ) q ϕ ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log q ϕ ( z ∣ x ) p ( x , z ) ] + E q ϕ ( z ∣ x ) [ log p ( z ∣ x ) q ϕ ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log q ϕ ( z ∣ x ) p ( x , z ) ] + D KL ( q ϕ ( z ∣ x ) ∥ p ( z ∣ x ) ) ≥ E q ϕ ( z ∣ x ) [ log q ϕ ( z ∣ x ) p ( x , z ) ]
因为KL散度(Kullback–Leibler Divergence ,或者叫相对熵)是非负的,所以能得到最后一步。此时,我们称log p ( x ) \log p(\boldsymbol{x}) log p ( x ) E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] \mathbb{E}_{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\left[\log \frac{p(\boldsymbol{x}, \boldsymbol{z})}{q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x})}\right] E q ϕ ( z ∣ x ) [ log q ϕ ( z ∣ x ) p ( x , z ) ]
log p ( x ) \log p(\boldsymbol{x}) log p ( x ) p p p θ \theta θ log p ( x ) \log p(\boldsymbol{x}) log p ( x ) log p ( x ) \log p(\boldsymbol{x}) log p ( x )
为什么去最大化ELBO能优化log p ( x ) \log p(\boldsymbol{x}) log p ( x ) log p ( x ) \log p(\boldsymbol{x}) log p ( x ) ϕ \phi ϕ ϕ \phi ϕ D K L ( q ϕ ( z ∣ x ) ∥ p ( z ∣ x ) ) D_{\mathrm{KL}}\left(q_{\phi}(\boldsymbol{z} \mid \boldsymbol{x}) \| p(\boldsymbol{z} \mid \boldsymbol{x})\right) D KL ( q ϕ ( z ∣ x ) ∥ p ( z ∣ x ) ) q ϕ q_{\phi} q ϕ p θ p_{\theta} p θ p ( x ) p(x) p ( x )
更详细与广泛的说明见这个Post 。
Overlook
既然DDPM是一种生成式的模型,那么就有必要对生成式模型 这个大家族进行一些介绍。对于其他生成式模型,我也不能说十分了解,也是看了一些皮毛,有错误欢迎指出与讨论🤗🤗
生成式模型(Generative Models ),顾名思义就是一种用于生成的模型,与之相对的比如判别式的模型,说得数学一些就是判别式的模型去直接学习一个条件概率密度分布,如果用X X X Y Y Y P ( Y ∣ X ) P(Y|X) P ( Y ∣ X ) P ( X , Y ) P(X,Y) P ( X , Y )
因此生成模型能够用于模拟(即生成)模型中任意变量的分布情况,而判别模型只能根据观测变量得到目标变量的采样。判别模型不对观测变量的分布建模,因此它不能够表达观测变量与目标变量之间更复杂的关系。因此,生成模型更适用于无监督的任务,如分类和聚类。
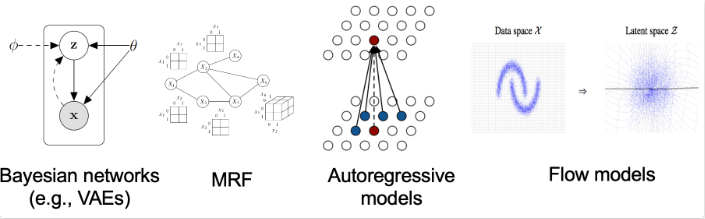
常见的生成式模型包括自回归模型、归一化流模型(Normalizing Flow)、基于能量的模型(EBMs)、变异自动编码器(VAEs)、以及对抗生成网络(GANs)和现在的去噪扩散概率模型(DDPM)。
在以前,这些模型根据根据其表示概率分布的方式可以大致分为两类:
基于似然的模型(Likelihood-based Models ),它通过(近似的)最大似然直接学习分布的概率密度函数。典型的基于似然的模型包括自回归模型、归一化流模型、基于能量的模型和变异自动编码器,所有这些模型都表示一个分布的概率密度或质量函数。
隐式生成模型(Implicit Generative Models ),其概率分布由采样过程的模型隐含表示。比如生成对抗网络(GANs),其数据分布的新样本是通过用神经网络转换随机高斯向量而合成的。
图都来自于宋飏博士的Blog
上述两种模型都存在一定的问题,比如基于似然的模型需要确保能够得到一个归一化常数 (用来确保概率之和为1的常数),如果无法计算归一化常数,则需要使用近似方法来进行最大似然训练。而GANs要训练生成器与判别器,在训练的过程需要对抗性训练,非常不稳定,可能导致模式崩溃 (Mode Collapse)。
对于归一化常数,举个🌰,对于一个连续的概率密度函数,我们对其进行积分,肯定要保证其积分为1,比如我们耳熟能详的高斯分布:f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)2}{2\sigma^2}} f ( x ) = 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 1 2 π σ \frac{1}{\sqrt{2\pi}\sigma} 2 π σ 1
为了使模型能够进行最大似然训练,我们需要对模型结构进行限制或使用近似方法,避免归一化常数的计算。
Score-based Models
为了解决上述两种模型存在的问题,一种基于分数 的模型(Score-based Models)横空出世。
其关键思想是对对数概率密度函数 的梯度进行建模,通常被称为(Stein)分数函数(Score Function)。这种基于分数的模型不需要有一个可计算的归一化常数,可以通过分数匹配(Score Matching)直接学习。
基于分数的模型与DDPM有很大的关系,因此要对分数模型进行介绍🤗(事实上,基于分数的模型和DDPM是同一事物的两种不同的解释,非常推荐宋飏大佬的这篇Blog:Generative Modeling by Estimating Gradients of the Data Distribution !🥳这一部分大部分都是基于这个Blog😁)
给定一些独立同分布的数据,即从p ( x ) p(x) p ( x ) { x 1 , x 2 , x 3 , . . . , x t } \{x_1,x_2,x_3,...,x_t\} { x 1 , x 2 , x 3 , ... , x t } p ( x ) p(x) p ( x ) p ( x ) p(x) p ( x )
p θ ( x ) = e − f θ ( x ) Z θ p_{\theta}(x)=\frac{e^{-f_{\theta}(x)}}{Z_{\theta}}
p θ ( x ) = Z θ e − f θ ( x )
其中,− f θ ( x ) ∈ R -f_{\theta}(x) \in \mathbb{R} − f θ ( x ) ∈ R 能量 的模型(Energy-based Model),Z θ > 0 Z_{\theta} > 0 Z θ > 0 θ \theta θ
max θ ∑ i = 1 N log p θ ( x i ) \max_{\theta } \sum_{i=1}^{N}\log p_{\theta}(x_i)
θ max i = 1 ∑ N log p θ ( x i )
至此,好像没啥特别的,我们还要去和最大似然模型一样去做这些很困难的任务🤔,比如像自回归模型的因果卷积、归一化流模型中的可逆网络,抑或是去估计归一化常数,比如VAE中的变分推理等等。
但是,换个角度,既然我们定义了f θ ( x ) f_{\theta}(x) f θ ( x ) 得分函数 (Score Function)的东西,对于p ( x ) p(x) p ( x )
∇ x log p ( x ) \nabla_{x}\log p(x)
∇ x log p ( x )
我们将基于得分函数的模型,就叫做基于分数的模型 (Score-based Model),假设模型为s θ s_{\theta} s θ s θ s_{\theta} s θ ∇ x log p ( x ) \nabla_{x}\log p(x) ∇ x log p ( x ) f θ ( x ) f_{\theta}(x) f θ ( x )
s θ ( x ) = ∇ x log p θ ( x ) = − ∇ x f θ ( x ) − ∇ x log Z θ ⏟ = 0 = − ∇ x f θ ( x ) \mathbf{s}_{\theta}(\mathbf{x})=\nabla_{\mathbf{x}}\log p_\theta(\mathbf{x})=-\nabla_\mathbf{x}f_\theta({\mathbf{x}})-\underbrace{\nabla_\mathbf x\log{Z}_\theta}_{=0}=-\nabla_\textbf x f_\theta(\mathbf x)
s θ ( x ) = ∇ x log p θ ( x ) = − ∇ x f θ ( x ) − = 0 ∇ x log Z θ = − ∇ x f θ ( x )
这样我们成功绕过了归一化常数(数学上)🎉,而且由于没有归一化常数的限制,我们可以随意扩展与修改模型。(在宋博的Blog上有可视化更直观😁)
通过最小化模型和数据分布之间的Fisher散度(Fisher Divergence )来训练基于分数的模型(衡量真实数据与基于分数的模型之间的l 2 l_2 l 2
E p ( x ) [ ∥ ∇ x log p ( x ) − s θ ( x ) ∥ 2 2 ] \mathbb{E}_{p(\mathbf{x})}[\|\nabla_\mathbf{x}\log p(\mathbf{x})-\mathbf{s}_\theta(\mathbf{x})\|_2^2]
E p ( x ) [ ∥ ∇ x log p ( x ) − s θ ( x ) ∥ 2 2 ]
我们没法直接计算∇ x log p ( x ) \nabla_\mathbf{x}\log p(\mathbf{x}) ∇ x log p ( x ) 分数匹配(Score Matching) ,能够在真实数据分布未知的情况下去最小化Fisher散度。它能直接在数据集上进行估计并进行优化(不需要考虑归一化常数,也不需要与GAN一样的对抗)。
综上所述,通过对分数函数进行建模,我们绕过了归一化常数的问题,并且有一个完备的优化它的方式。但是我们的建模是∇ x log p ( x ) \nabla_{x}\log p(x) ∇ x log p ( x ) p ( x ) p(x) p ( x ) 朗之万动力学 (Langevin Dynamics)。
Langevin Dynamics
与SGDM的灵感来源类似,分数模型的采样过程也来源于物理学,即朗之万动力学 ,它允许我们从一个任意的分布,只根据∇ x log p ( x ) \nabla_\mathbf{x}\log p(\mathbf{x}) ∇ x log p ( x ) x 0 x_{0} x 0
x i + 1 ← x i + ϵ ∇ x log p ( x ) + 2 ϵ z i , i = 0 , 1 , ⋯ , K x_{i+1}\leftarrow x_i+\epsilon\nabla_x\log p(x)+\sqrt{2\epsilon}\mathbf{z}_i,\quad i=0,1,\cdots,K
x i + 1 ← x i + ϵ ∇ x log p ( x ) + 2 ϵ z i , i = 0 , 1 , ⋯ , K
其中,z i ∼ N ( 0 , I ) \mathbf{z}_i \sim \mathcal{N}(0,I) z i ∼ N ( 0 , I ) ϵ → 0 \epsilon \to 0 ϵ → 0 时, 时, 时, 就会近似于从 就会近似于从 就会近似于从
这样我们就建立起了得分函数和采样之间的联系🎉
Discussion
基于分数的模型看似完备的过程其实也存在问题,比如在最小化期望的时候:
E p ( x ) [ ∥ ∇ x log p ( x ) − s θ ( x ) ∥ 2 2 ] = ∫ p ( x ) ∥ ∇ x log p ( x ) − s θ ( x ) ∥ 2 2 d x \mathbb{E}_{p(\mathbf{x})}[\lVert\nabla_{\mathbf{x}}\log p(\mathbf{x})-\mathbf{s}_{\theta}(\mathbf{x})\rVert_2^2]=\int p(\mathbf{x})\lVert\nabla_\mathbf{x}\log p({\mathbf{x}})-\mathbf{s}_\theta({\mathbf{x}})\rVert_2^2\mathrm{dx}
E p ( x ) [∥ ∇ x log p ( x ) − s θ ( x ) ∥ 2 2 ] = ∫ p ( x ) ∥ ∇ x log p ( x ) − s θ ( x ) ∥ 2 2 dx
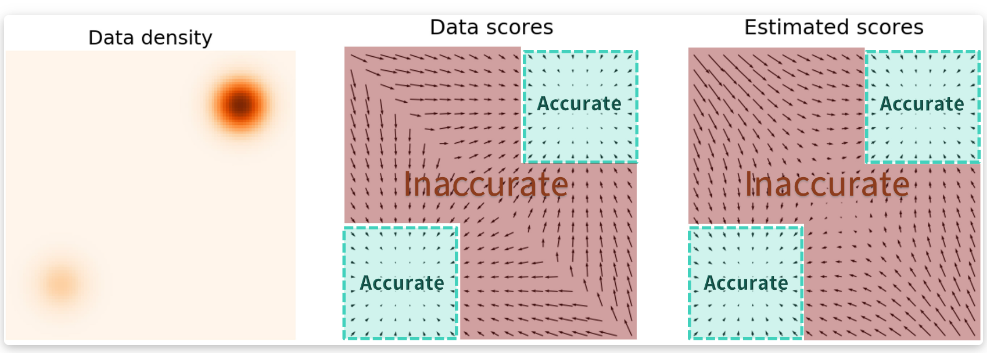
相当于给l 2 l_2 l 2 p ( x ) p(x) p ( x )
当数据位于高维空间时,我们的初始分布极有可能处于低密度区域,原因见这里 。此时如果再有一个不准确的基于分数的模型,从一开始就将使分布偏离了正轨,使其无法产生代表数据的高质量样本。
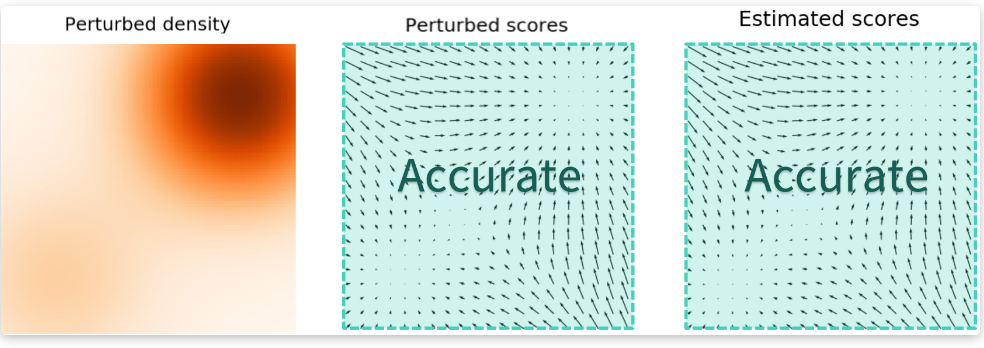
类似于我们在一张HDR图片上做优化时要给亮部分和暗的部分一个平衡,不然整张图片都会被亮部决定。我们也要给原数据一些处理,让它们的分布更加“合理”,这个办法就是加高斯噪声🦄。当噪声尺度足够大时,它可以填充低数据密度区域以提高估计分数的准确性:
另一个问题在于:较大的噪声可以使分布更模糊能获得更好的分数估计,但它会过度破坏原始数据;较小的噪声不能很充分覆盖低密度区域。我们还是需要一个权衡🤔。采用多个尺度的噪声扰动的方式,假设有σ 1 < σ 2 < ⋯ < σ L \sigma_1<\sigma_2<\cdots<\sigma_L σ 1 < σ 2 < ⋯ < σ L N ( 0 , σ i 2 I ) , i = 1 , 2 , ⋯ , L \mathcal{N}(0,\sigma_i^2I),i=1,2,\cdots,L N ( 0 , σ i 2 I ) , i = 1 , 2 , ⋯ , L
p σ i ( x ) = ∫ p ( y ) N ( x ; y , σ i 2 I ) d y p_{\sigma_i}(\mathbf{x})=\int p(\mathbf{y})\mathcal{N}(\mathbf{x};\mathbf{y},\sigma_i^2I)\mathrm{dy}
p σ i ( x ) = ∫ p ( y ) N ( x ; y , σ i 2 I ) dy
接下来就能计算得分函数∇ x log p σ i ( x ) \nabla_\mathbf{x}\log p_{\sigma_i}(\mathbf{x}) ∇ x log p σ i ( x ) NCSN Noise Conditional Score-based Model )。训练的目标相应变为各个尺度的加权:
∑ i = 1 L λ ( i ) E p σ i ( x ) [ ∥ ∇ x log p σ i ( x ) − s θ ( x , i ) ∥ 2 2 ] \sum_{i=1}^{L} \lambda(i) \mathbb{E}_{p_{\sigma_{i}}(\mathbf{x})}\left[\left\|\nabla_{\mathbf{x}} \log p_{\sigma_{i}}(\mathbf{x})-\mathbf{s}_{\theta}(\mathbf{x}, i)\right\|_{2}^{2}\right]
i = 1 ∑ L λ ( i ) E p σ i ( x ) [ ∥ ∇ x log p σ i ( x ) − s θ ( x , i ) ∥ 2 2 ]
权重通常设为λ ( i ) = σ i 2 \lambda(i)=\sigma_i^2 λ ( i ) = σ i 2
如果读过近期的扩散模型的论文,会发现其实很多时候扩散模型也被称为 Score-based Diffusion Models,以及很多关于SDE的文章(尤其是I2I任务)也会被归为扩散/分数家族🤯 。
这里,我们定义SDE为:
d x = f ( x , t ) d t + g ( t ) d w d\mathbf{x}=\mathbf{f}(\mathbf{x},t)dt+g(t)d\mathbf{w}
d x = f ( x , t ) d t + g ( t ) d w
f ( ∗ , t ) \mathbf{f}(*, t) f ( ∗ , t ) g ( t ) g(t) g ( t ) w \mathbf{w} w
d x = [ f ( x , t ) − g 2 ( t ) ∇ x log p t ( x ) ] d t + g ( t ) d w ˉ d\mathbf{x}=[\mathbf{f}(\mathbf{x},t)-g^2(t)\nabla_\mathbf{x}\log p_t(\mathbf{x})]dt+g(t)d \bar{\mathbf{w}}
d x = [ f ( x , t ) − g 2 ( t ) ∇ x log p t ( x )] d t + g ( t ) d w ˉ
其中w ˉ \bar{\mathbf{w}} w ˉ d t dt d t 负时间 的。因此,如果知道了漂移系数、扩散系数以及分布每个时间的分数,我们就能得到这个逆向的过程🥳
整个过程就是(和DDPM已经非常非常像了):
我们来介绍一下主角:扩散模型🤗。
基于分数的模型还有很多可以扩展的,比如SDE的相关工作,以及本文没讲到的损失函数推导,毕竟重心并不是它们😁,在有了一点基于分数的模型直觉之后,对扩散家族能更好理解。
PS:更多内容再次推荐宋飏大佬的Blog !
Diffusion Model
Miscellaneous
扩散模型与基于分数的模型类似(准确来说对图像进行噪声扰动的处理是常见的数据处理方式),我在第一次接触基于分数的模型和DDPM的时候一头雾水🫥,在不同的论文里面术语用的非常混乱,比如会把DDPM说成Score-based diffusion model的相关工作,一些22年、23年的开源的关于SDE的工作甚至也是基于Guided-diffusion框架,这让我更加一头雾水😣,不知道他们是不是一种东西。在深入了解之后,确实如宋飏博士说的:
Collectively, these latest developments seem to indicate that both score-based generative modeling with multiple noise perturbations and diffusion probabilistic models are different perspectives of the same model family, much like how wave mechanics and matrix mechanics are equivalent formulations of quantum mechanics in the history of physics.
Many recent works on score-based generative models or diffusion probabilistic models have been deeply influenced by knowledge from both sides of research (see a website curated by researchers at the University of Oxford). Despite this deep connection between score-based generative models and diffusion models, it is hard to come up with an umbrella term for the model family that they both belong to. Some colleagues in DeepMind propose to call them “Generative Diffusion Processes”. It remains to be seen if this will be adopted by the community in the future.
也许后续会把这两种模型合二为一,互相取长补短🤔,所以我介绍了一些关于基于分数的模型的内容。
Overlook
既然叫“扩散”模型,那肯定就要和物理学联系起来了😁,自然界总是朝着无序的方向发展,变得混乱,一张噪声图也可以看作是像素们逐渐 “扩散”了,那有没有一种方式让这个过程可逆,找到这样的一种可逆的方式(模型),我们就能随便拿出一张“扩散了的”图像丢给模型让它给我们输出一张正常的图片。说到这,很简单的思想就是我们把每一步扩散的过程都反转过去(两极反转!),DDPM就是这样做的🤫
反转噪声不是一步到位的,而是一步一步反转的,这就要求我们要把扩散的不同程度的图像都要给模型进行训练,但是我们去哪找这些图像?自己造!我们给图像添加高斯噪声,通过给定扩散程度t t t t t t
推导部分参考于原论文 与Lil’Log 🤗
Forward Diffusion Process➡️
前向过程
正如前面所述,给定一个图片x 0 x_0 x 0 { x 1 , x 2 , . . . , x T } \{x_1,x_2,...,x_T\} { x 1 , x 2 , ... , x T } T T T
更加动态的过程:
现在我们有一个先验的知识就是,图像到最后会被我们变成一个标准高斯噪声 图像,那么我们就可以定义一个条件概率,以前一张图作为条件,生成下一步的图:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) \text{q}\left(\mathbf x_t\mid\mathbf x_{t-1}\right)=\mathcal N\left(\mathbf x_t;\sqrt{1-\beta_t}\mathbf x_{t-1},\beta_t\mathbf I\right)
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I )
β ∈ ( 0 , 1 ) \beta \in (0,1) β ∈ ( 0 , 1 ) t t t β \beta β β = 1 \beta =1 β = 1
根据高斯分布的重参数化技术,x x x
x = μ ( ϕ ) + σ ( ϕ ) ∗ ϵ x=\mu(\phi)+\sigma(\phi)*\epsilon
x = μ ( ϕ ) + σ ( ϕ ) ∗ ϵ
则条件概率重写为(把均值与方差代入):
x t = 1 − β t x t − 1 + β t ϵ t − 1 x_t=\sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}\epsilon_{t-1}
x t = 1 − β t x t − 1 + β t ϵ t − 1
这样我们就把条件概率的具体形式写出来了,并且无需考虑因为采样不可微而导致的梯度不能传播问题(可以写代码了🤣!)。但是到这还不够,刚刚说到T T T T T T
为了方便推导,现在我们假设ϵ ∼ N ( 0 , 1 ) \epsilon \sim N(0,1) ϵ ∼ N ( 0 , 1 ) α t = 1 − β t \alpha_t=1-\beta_t α t = 1 − β t α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t=\prod_{i=1}^t\alpha_i α ˉ t = ∏ i = 1 t α i
x t = α t x t − 1 + 1 − α t ϵ t − 1 = α t ( α t − 1 x t − 2 + 1 − α t − 1 ϵ t − 2 ) + 1 − α t ϵ t − 1 = α t α t − 1 x t − 2 + ( α t ( 1 − α t − 1 ) ϵ t − 2 + 1 − α t ϵ t − 1 ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ t − 2 = … = α ˉ t x 0 + 1 − α ˉ t ϵ \begin{aligned}
\mathbf{x}_{t} & =\sqrt{\alpha_{t}} \mathbf{x}_{t-1}+\sqrt{1-\alpha_{t}} \epsilon_{t-1} \\
& =\sqrt{\alpha_{t}}\left(\sqrt{\alpha_{t-1}} \mathbf{x}_{t-2}+\sqrt{1-\alpha_{t-1}} \epsilon_{t-2}\right)+\sqrt{1-\alpha_{t}} \epsilon_{t-1} \\
& =\sqrt{\alpha_{t} \alpha_{t-1}} \mathbf{x}_{t-2}+\left(\sqrt{\alpha_{t}\left(1-\alpha_{t-1}\right)} \epsilon_{t-2}+\sqrt{1-\alpha_{t}} \epsilon_{t-1}\right) \\
& =\sqrt{\alpha_{t} \alpha_{t-1}} \mathbf{x}_{t-2}+\sqrt{1-\alpha_{t} \alpha_{t-1}} \bar{\epsilon}_{t-2} \\
& =\ldots \\
& =\sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}} \epsilon
\end{aligned}
x t = α t x t − 1 + 1 − α t ϵ t − 1 = α t ( α t − 1 x t − 2 + 1 − α t − 1 ϵ t − 2 ) + 1 − α t ϵ t − 1 = α t α t − 1 x t − 2 + ( α t ( 1 − α t − 1 ) ϵ t − 2 + 1 − α t ϵ t − 1 ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ t − 2 = … = α ˉ t x 0 + 1 − α ˉ t ϵ
经过推导,我们实际上得到了q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(\mathbf x_t|\mathbf x_0)=\mathcal N(\mathbf x_t;\sqrt{\bar\alpha_t}\mathbf x_0,(1-\bar\alpha_t)\mathbf I) q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I )
Reverse Diffusion Process⬅️
后向过程
在得到了{ x 1 , x 2 , . . . , x T } \{x_1,x_2,...,x_T\} { x 1 , x 2 , ... , x T } β \beta β
q ( x t − 1 ∣ x t ) = N ( x t − 1 ; 1 − β t − 1 x t , β t − 1 I ) \text{q}\left(\mathbf x_{t-1}\mid\mathbf x_{t}\right)=\mathcal N\left(\mathbf x_{t-1};\sqrt{1-\beta_{t-1}}\mathbf x_{t},\beta_{t-1}\mathbf I\right)
q ( x t − 1 ∣ x t ) = N ( x t − 1 ; 1 − β t − 1 x t , β t − 1 I )
通过后向过程,我们就可以把一个噪声图恢复:
但是我们并不能和前向过程一样,因为我们没有一个先验的知识告诉我们图像的分布是怎么样的,比如拍了一张照片,我们没法直接写出它的分布情况。除非我们把所有的图像的像素做一个统计,然后去拟合,这工作量是不可能的🫥。
因此我们可以通过深度学习模型去拟合这个分布。假设我们拟合的这个分布是:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_{\theta}\left(\mathbf{x}_{t-1}\mid\mathbf{x_t}\right)=\mathcal{N}\left(\mathbf{x_{t-1}};
\mu_\theta \left(\mathbf{x_t},t\right),\Sigma_\theta\left({\mathbf{x_t}},t\right)\right)
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) )
为了得到这个分布的具体形式,作者通过一个很巧妙的裂项法,把求后向过程的概率转化成前向过程的概率的组合形式,根据贝叶斯与条件概率公式(推导中β \beta β α \alpha α
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 ⏟ x t − 1 方差 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 ⏟ x t − 1 均值 + C ( x t , x 0 ) ⏟ 与 x t − 1 无关 ) ) \begin{aligned}
&q\left(x_{t-1} \mid x_{t}, x_{0}\right) =q\left(x_{t} \mid x_{t-1}, x_{0}\right) \frac{q\left(x_{t-1} \mid x_{0}\right)}{q\left(x_{t} \mid x_{0}\right)} \\
& \propto \exp \left(-\frac{1}{2}\left(\frac{\left(x_{t}-\sqrt{\alpha_{t}} x_{t-1}\right)^{2}}{\beta_{t}}+\frac{\left(x_{t-1}-\sqrt{\bar{\alpha}_{t-1}} x_{0}\right)^{2}}{1-\bar{\alpha}_{t-1}}-\frac{\left(x_{t}-\sqrt{\bar{\alpha}_{t}} x_{0}\right)^{2}}{1-\bar{\alpha}_{t}}\right)\right) \\
&=\exp \\
&\left(-\frac{1}{2}(\underbrace{\left(\frac{\alpha_{t}}{\beta_{t}}+\frac{1}{1-\bar{\alpha}_{t-1}}\right) x_{t-1}^{2}}_{x_{t-1} \text { 方差 }}-\underbrace{\left(\frac{2 \sqrt{\alpha_{t}}}{\beta_{t}} x_{t}+\frac{2 \sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}} x_{0}\right) x_{t-1}}_{x_{t-1} \text { 均值 }}+\underbrace{C\left(x_{t}, x_{0}\right)}_{\text {与 } x_{t-1} \text { 无关 }})\right)
\end{aligned}
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ∝ exp ( − 2 1 ( β t ( x t − α t x t − 1 ) 2 + 1 − α ˉ t − 1 ( x t − 1 − α ˉ t − 1 x 0 ) 2 − 1 − α ˉ t ( x t − α ˉ t x 0 ) 2 ) ) = exp − 2 1 ( x t − 1 方差 ( β t α t + 1 − α ˉ t − 1 1 ) x t − 1 2 − x t − 1 均值 ( β t 2 α t x t + 1 − α ˉ t − 1 2 α ˉ t − 1 x 0 ) x t − 1 + 与 x t − 1 无关 C ( x t , x 0 ) )
标准的高斯分布形式:
exp ( − ( x − μ ) 2 2 σ 2 ) = exp ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) \exp{\left(-\dfrac{(x-\mu)^2}{2\sigma^2}\right)}=\exp\left(-\dfrac12\left(\dfrac1{\sigma^2}x^2-\dfrac{2\mu}{\sigma^2}x+\dfrac{\mu^2}{\sigma^2}\right)\right)
exp ( − 2 σ 2 ( x − μ ) 2 ) = exp ( − 2 1 ( σ 2 1 x 2 − σ 2 2 μ x + σ 2 μ 2 ) )
二者对比可以得到:
μ ~ t ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \tilde{\mu}_{t}\left(x_{t}, x_{0}\right)=\frac{\sqrt{\alpha_{t}}\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_{t}} x_{t}+\frac{\sqrt{\bar{\alpha}_{t-1}} \beta_{t}}{1-\bar{\alpha}_{t}} x_{0}
μ ~ t ( x t , x 0 ) = 1 − α ˉ t α t ( 1 − α ˉ t − 1 ) x t + 1 − α ˉ t α ˉ t − 1 β t x 0
1 σ 2 = 1 β ~ t = ( α t β t + 1 1 − α ˉ t − 1 ) \frac{1}{\sigma^{2}}=\frac{1}{\tilde{\beta}_{t}}=\left(\frac{\alpha_{t}}{\beta_{t}}+\frac{1}{1-\bar{\alpha}_{t-1}}\right)
σ 2 1 = β ~ t 1 = ( β t α t + 1 − α ˉ t − 1 1 )
无关项忽略不管,这样我们就得到了方差与均值,但是均值里面还带着一个x 0 x_0 x 0 x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_{t}=\sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon} x t = α ˉ t x 0 + 1 − α ˉ t ϵ x 0 x_0 x 0
μ ~ t = 1 α t ( x t − β t 1 − α ˉ t ϵ ) \tilde{\mu}_{t}=\frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \boldsymbol{\epsilon} \right)
μ ~ t = α t 1 ( x t − 1 − α ˉ t β t ϵ )
到这一步后向过程就完成了定义,首先可以发现,方差是固定不变的,只与超参数β \beta β α \alpha α t − 1 t-1 t − 1 x t x_t x t ϵ \epsilon ϵ
Mini Summary
现在我们知道了扩散模型的运作原理,现在,给定一张被噪声扰动的图像x t x_t x t x t − 1 x_{t-1} x t − 1
把x t x_t x t ϵ \epsilon ϵ
噪声代入1 α t ( x t − β t 1 − α ˉ t ϵ ) \frac{1}{\sqrt{\alpha_{t}}}\left(x_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \boldsymbol{\epsilon} \right) α t 1 ( x t − 1 − α ˉ t β t ϵ ) x t − 1 x_{t-1} x t − 1
根据超参数α \alpha α β \beta β
把方差与均值代入重参数化后的计算式中,得到x t − 1 x_{t-1} x t − 1
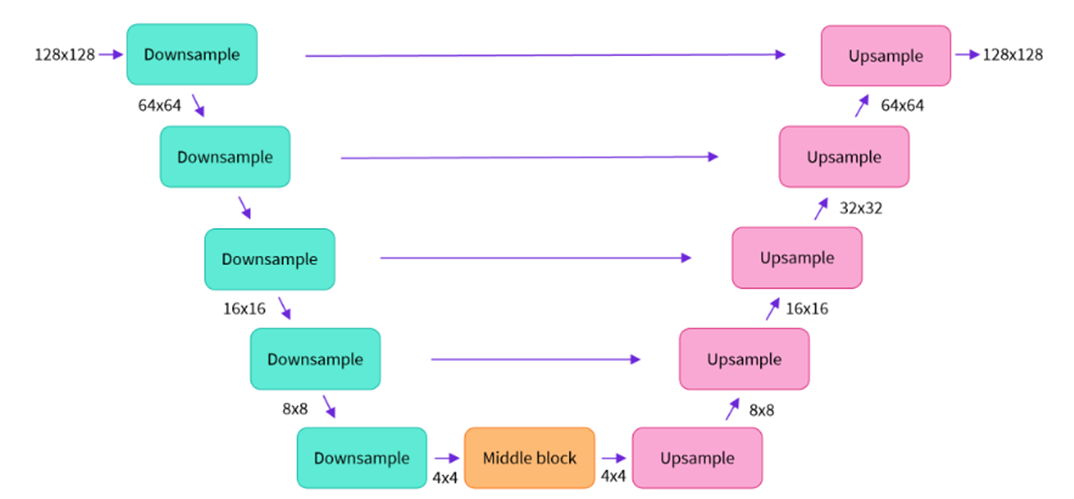
所以我们选择的网络应该至少有这样的功能:输入一张图像,输出的内容应该与输入图像相同大小、通道数一致(可选)。扩散模型家族选择了U-Net 网络,简要的网络结构:
至此,我们还差最后一步,就是模型要怎么训练,即损失函数要如何定义🤔
Loss
我们最终要用网络去拟合真实的p θ ( x 0 ) p_{\theta}(x_0) p θ ( x 0 )
根据后向过程我们可以发现它这个过程可以看作是一个多步、隐变量大小与图像相同的VAE,因此扩散模型的ELBO要联合所有时间T T T
L = E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = E q [ log ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 1 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ⋅ q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + ∑ t = 2 T log q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E q [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] = E q [ D K L ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) ⏟ L T + ∑ t = 2 T D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ⏟ L t − 1 − log p θ ( x 0 ∣ x 1 ) ⏟ L 0 ] \begin{array}{l}
L=\mathbb{E}_{q\left(\mathbf{x}_{0: T)}\right.}\left[\log \frac{q\left(\mathbf{x}_{1: T} \mid \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{0: T}\right)}\right] \\
=\mathbb{E}_{q}\left[\log \frac{\prod_{t=1}^{T} q\left(\mathbf{x}_{t} \mid \mathbf{x}_{t-1}\right)}{p_{\theta}\left(\mathbf{x}_{T}\right) \prod_{t=1}^{T} p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)}\right] \\
=\mathbb{E}_{q}\left[-\log p_{\theta}\left(\mathbf{x}_{T}\right)+\sum_{t=1}^{T} \log \frac{q\left(\mathbf{x}_{t} \mid \mathbf{x}_{t-1}\right)}{p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)}\right] \\
=\mathbb{E}_{q}\left[-\log p_{\theta}\left(\mathbf{x}_{T}\right)+\sum_{t=2}^{T} \log \frac{q\left(\mathbf{x}_{t} \mid \mathbf{x}_{t-1}\right)}{p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)}+\log \frac{q\left(\mathbf{x}_{1} \mid \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{0} \mid \mathbf{x}_{1}\right)}\right] \\
=\mathbb{E}_{q}\left[-\log p_{\theta}\left(\mathbf{x}_{T}\right)+\sum_{t=2}^{T} \log \left(\frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)} \cdot \frac{q\left(\mathbf{x}_{t} \mid \mathbf{x}_{0}\right)}{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{0}\right)}\right)+\log \frac{q\left(\mathbf{x}_{1} \mid \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{0} \mid \mathbf{x}_{1}\right)}\right] \\
=\mathbb{E}_{q}\left[-\log p_{\theta}\left(\mathbf{x}_{T}\right)+\sum_{t=2}^{T} \log \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)}+\sum_{t=2}^{T} \log \frac{q\left(\mathbf{x}_{t} \mid \mathbf{x}_{0}\right)}{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{0}\right)}+\log \frac{q\left(\mathbf{x}_{1} \mid \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{0} \mid \mathbf{x}_{1}\right)}\right] \\
=\mathbb{E}_{q}\left[-\log p_{\theta}\left(\mathbf{x}_{T}\right)+\sum_{t=2}^{T} \log \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)}+\log \frac{q\left(\mathbf{x}_{T} \mid \mathbf{x}_{0}\right)}{q\left(\mathbf{x}_{1} \mid \mathbf{x}_{0}\right)}+\log \frac{q\left(\mathbf{x}_{1} \mid \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{0} \mid \mathbf{x}_{1}\right)}\right] \\
=\mathbb{E}_{q}\left[\log \frac{q\left(\mathbf{x}_{T} \mid \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{T}\right)}+\sum_{t=2}^{T} \log \frac{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathbf{x}_{0}\right)}{p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)}-\log p_{\theta}\left(\mathbf{x}_{0} \mid \mathbf{x}_{1}\right)\right] \\
=\mathbb{E}_{q}[\underbrace{D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{T} \mid \mathbf{x}_{0}\right) \| p_{\theta}\left(\mathbf{x}_{T}\right)\right)}_{L_{T}}
+\sum_{t=2}^{T} \underbrace{D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}, \mathbf{x}_{0}\right) \| p_{\theta}\left(\mathbf{x}_{t-1} \mid \mathbf{x}_{t}\right)\right)}_{L_{t-1}}-\underbrace{\log p_{\theta}\left(\mathbf{x}_{0} \mid \mathbf{x}_{1}\right)}_{L_{0}}] \\
\end{array}
L = E q ( x 0 : T ) [ log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] = E q [ log p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ∏ t = 1 T q ( x t ∣ x t − 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 1 T log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log ( p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) ⋅ q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) + ∑ t = 2 T log q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] = E q [ − log p θ ( x T ) + ∑ t = 2 T log p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) + log q ( x 1 ∣ x 0 ) q ( x T ∣ x 0 ) + log p θ ( x 0 ∣ x 1 ) q ( x 1 ∣ x 0 ) ] = E q [ log p θ ( x T ) q ( x T ∣ x 0 ) + ∑ t = 2 T log p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x t , x 0 ) − log p θ ( x 0 ∣ x 1 ) ] = E q [ L T D KL ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) + ∑ t = 2 T L t − 1 D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) − L 0 log p θ ( x 0 ∣ x 1 ) ]
L T L_T L T L 0 L_0 L 0 N ( x 0 ; μ θ ( x 1 , 1 ) , Σ θ ( x 1 , 1 ) ) N(\textbf{x}_0;\boldsymbol{\mu}_\theta(\textbf{x}_1,1),\boldsymbol{\Sigma}_\theta({\textbf{x}_1},1)) N ( x 0 ; μ θ ( x 1 , 1 ) , Σ θ ( x 1 , 1 )) L t − 1 L_{t-1} L t − 1
由于我们是在预测噪声,因此我们可以简化中间这些项——直接计算预测的噪声与我们加入的噪声的相似度(MSE损失):
L t = E x 0 , ϵ [ 1 2 ∥ Σ θ ( x t , t ) ∥ 2 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 1 2 ∥ Σ θ ∥ 2 2 ∥ 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) − 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{array}{l}
L_{t}=\mathbb{E}_{\mathbf{x}_{0}, \boldsymbol{\epsilon}}\left[\frac{1}{2\left\|\mathbf{\Sigma}_{\theta}\left(\mathbf{x}_{t}, t\right)\right\|_{2}^{2}}\left\|\tilde{\boldsymbol{\mu}}_{t}\left(\mathbf{x}_{t}, \mathbf{x}_{0}\right)-\boldsymbol{\mu}_{\theta}\left(\mathbf{x}_{t}, t\right)\right\|^{2}\right] \\
=\mathbb{E}_{\mathbf{x}_{0,} \boldsymbol{\epsilon}}\left[\frac{1}{2\left\|\boldsymbol{\Sigma}_{\theta}\right\|_{2}^{2}}\left\|\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{x}_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \boldsymbol{\epsilon}_{t}\right)-\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{x}_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \boldsymbol{\epsilon}_{\theta}\left(\mathbf{x}_{t}, t\right)\right)\right\|^{2}\right] \\
=\mathbb{E}_{\mathbf{x}_{0}, \boldsymbol{\epsilon}}\left[\frac{\left(1-\alpha_{t}\right)^{2}}{2 \alpha_{t}\left(1-\bar{\alpha}_{t}\right)\left\|\boldsymbol{\Sigma}_{\theta}\right\|_{2}^{2}}\left\|\boldsymbol{\epsilon}_{t}-\boldsymbol{\epsilon}_{\theta}\left(\mathbf{x}_{t}, t\right)\right\|^{2}\right] \\
=\mathbb{E}_{\mathbf{x}_{0},\epsilon}\left[\frac{\left(1-\alpha_{t}\right)^{2}}{2 \alpha_{t}\left(1-\bar{\alpha}_{t}\right)\left\|\mathbf{\Sigma}_{\theta}\right\|_{2}^{2}}\left\|\boldsymbol{\epsilon}_{t}-\boldsymbol{\epsilon}_{\theta}\left(\sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon}_{t}, t\right)\right\|^{2}\right] \\
\end{array}
L t = E x 0 , ϵ [ 2 ∥ Σ θ ( x t , t ) ∥ 2 2 1 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 2 ∥ Σ θ ∥ 2 2 1 α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ t ) − α t 1 ( x t − 1 − α ˉ t 1 − α t ϵ θ ( x t , t ) ) 2 ] = E x 0 , ϵ [ 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ( 1 − α t ) 2 ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E x 0 , ϵ [ 2 α t ( 1 − α ˉ t ) ∥ Σ θ ∥ 2 2 ( 1 − α t ) 2 ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) 2 ]
在DDPM的论文中作者通过实验发现,把期望内的系数去掉模型会训练得更好,因此得到:
L t simple = E t ∼ [ 1 , T ] , x 0 , ϵ , ϵ t [ ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{aligned}
L_{t}^{\text {simple }} & =\mathbb{E}_{t \sim[1, T], \mathbf{x}_{0, \epsilon}, \epsilon_{t}}\left[\left\|\boldsymbol{\epsilon}_{t}-\boldsymbol{\epsilon}_{\theta}\left(\mathbf{x}_{t}, t\right)\right\|^{2}\right] \\
& =\mathbb{E}_{t \sim[1, T], \mathbf{x} 0, \epsilon_{t}}\left[\left\|\boldsymbol{\epsilon}_{t}-\boldsymbol{\epsilon}_{\theta}\left(\sqrt{\bar{\alpha}_{t} \mathbf{x}_{0}}+\sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon}_{t}, t\right)\right\|^{2}\right]
\end{aligned}
L t simple = E t ∼ [ 1 , T ] , x 0 , ϵ , ϵ t [ ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] = E t ∼ [ 1 , T ] , x 0 , ϵ t [ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) 2 ]
Postscript
与GAN相比,扩散家族有较强的理论与数学过程,可解释性较强;并且可以生成高质量与多样的图像;最重要的是,它们在训练过程中不需要对抗过程,训练过程更稳定。
另一方面,扩散模型训练过程资源消耗大;生成一张图片的采样过程耗时长;并且同样可能会受到数据集先验分布的影响,比如用狗🐕的训练集去训练不会生成猫🐱(但是比GAN能生成更多样式的狗狗)。
因此从DDPM被提出以来,很多工作都基于DDPM进行了改进,并且用于不同的任务中:
引入条件去引导,将无条件的DDPM扩展为有条件,比如增加类别特征参与训练(Classifier-guidance),或者加入文本引导;
改进模型的参数,改变U-Net的网络结构使模型适合不同的任务;
改进采样的速度:使模型在牺牲可接受精度的前提下大大提高采样速率;
与基于分数的模型结合,提出很多基于SDE引导的扩散模型;
在图像的其他任务上广泛运用,比如分割、去噪、图像修补等;
引入到其他任务中,比如语音等。
比较有影响力的模型包括有DDIM 、SDEdit 、ILVR 等等,以及OpenAI提出的两个框架Improved-diffusion 以及guided-diffusion ,很多工作的代码都是基于这两个框架🤗,十分推荐认真研读。当然,我也有一个Toy-project 来体验(生成动漫头像)。
最后,本文是我研究Diffusion模型以来的一些总结,难免会有纰漏和讲得不充分的地方👻,希望能抛砖引玉。
Reference
Reverse Time Stochastic Differential Equations for generative modelling High-Dimensional Space Normal distribution - Wikipedia The evidence lower bound (ELBO) From Autoencoder to Beta-VAE The Reparameterization Trick – Emma Benjaminson Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song What are Diffusion Models? | Lil’Log